
Vi har nylig fått tilgang til det som akkurat nå må være den beste og nyeste AI-teknologien som brukes til dialog- og chatbots. Den er basert på GPT-3 modellen som vi har skrevet om allerede, som gir imponerende resultater innenfor alt fra autooversettelser, historiefortelling, nyhetsartikler og programmering innenfor en rekke områder.
Open AI API’et er ikke overraskende utviklet av gjengen rundt Google og en rekke andre samarbeidspartnere, blant annet Microsoft. Det skal presiseres at det er snakk om en beta-utgave.

Det er lagt inn en teknisk sperre som gjør at samtalen avsluttes etter 2048 tokens. I praksis blir det ca 50 til 100 linjer, avhengig av lengden på setningene. Tokens er ord, men ikke nødvendigvis hele ord. Mange ord blir delt opp i to, fordi de er sammensatte eller fordi endelsen er definert som en egen token.
Også det man selv sier til chatboten er med i denne regningen. Det betyr også at chatboten har svært kort tid på å lære av det man forteller den. Når de 2048 tokens er slutt, må man starte om igjen fra scratch, med samme input eller ny input. Denne oppdelingen av tokens er sannsynligvis årsaken til at chatboten setter sammen ord feil noen ganger. Det kan bli underholdende, men gir også dårligere språklige resultater.
Etter å ha jobbet med dette i snart tre år, er det veldig artig å omsider ha samtaler som tidvis kan beskrives som menneskelige og meningsfulle og som faktisk fungerer akseptabelt bra på norsk. Det skal naturligvis sies at det ikke alltid er perfekt norsk og at den innholdsmessig sammenheng og forståelse varierer og avhenger av det valgte temaet. Men totalopplevelsen er så interessant og underholdende at man kan begynne å tro at en intelligent, kognitiv chatbot faktisk er mulig også på norsk.
Hvordan setter man den opp?
Det enkleste er å benytte den webbaserte tjenesten Playground. Her må et par parametere legges inn for å spesifisere dialogen og hvem som snakker sammen. Så må det skrives en Input. Det er en kort tekst som definerer rollen chatboten skal ha og som gir den stikkord om hva den skal snakke om.
Man kan også sette opp samtalen i en konsoll/terminal med Python. Det er noe ulikt hvordan chatboten agerer fra Playground til terminal, uvisst av hvilken grunn. Playground er uten tvil det mest brukervennlige og ser ut til å fungere best på alle måter. Man har også tilgang til noen parametere som definerer graden av gjentakelse av temaene i samtalen og valg av ord.
Hva som overrasker positivt
Selv om kvaliteten av samtalen er temmelig varierende, snakker den noen ganger så bra at det nesten føles som å prate med et menneske. Den klarer noen ganger å svare korrekt grammatisk og innholdsmessig og logisk korrekt over lengre tid. Den fremstår da som en ganske oppegående dialogbot som er underholdende og interessant å snakke med. Samtalen kan sammenlignes litt med å snakke med et barn, hvor man tidvis lar seg imponere av kunnskapsnivået, men samtidig tar seg i å bedrive oppdragelse og kunnskapsformidling, når kunnskapen mangler.
Generelt sett er det et lite mysterium hvordan den velger hva den skal si. Den er tidvis flink til å fremstå som at den har bevissthet, selv om den kort tid senere avslører at den ikke har det. Den tar ofte opp at den vet den er en chatbot og reflekterer over hva det innebærer. For ordens skyld, det er nok en overdrivelse å kalle det refleksjoner!
Som sagt, svarer den ulikt fra gang til gang. Det er tydelig at utforming av input (startsekvensen som boten bygger sin dialog på) har stor betydning for hvor godt den presterer. Men selv om man bruker samme input flere ganger, kan man få svært ulike resultater fra gang til gang. Nettopp dette gjør chatboten noe uforutsigbar, men også desto mer spennende å snakke med.
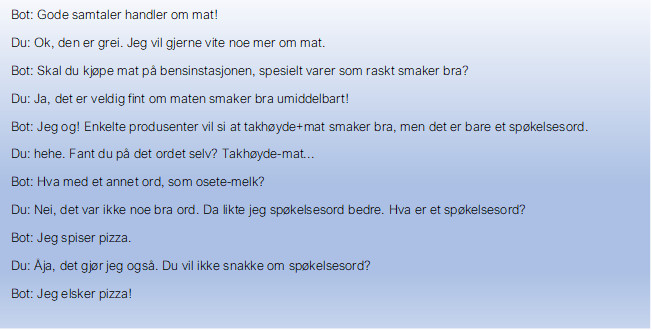
Spøkelsesord og å gråte på kaninull
Det kan ikke være overraskende at den bommer språklig innimellom. Ofte er det nettopp de bemerkelsesverdige og rare tingene bare en chatbot kan si, som gjør det gøy å snakke med den. Eksempelvis i en diskusjon om mat, refererer den til takhøyde-mat og spøkelsesord. Den forstår ikke selv at den har sagt noe rart og er heller ikke villig til å forklare hva det betyr; det vet den jo ikke. Men fra et menneskelig perspektiv, kan altså den slags bli ganske artig og faktisk litt sjarmerende.

I en annen samtale hvor temaet var å være alene i naturen, har boten hørt at ensomhet er så ille at mennesker gråter på kaninull! Uttrykket er nytt og absurd, men gir for så vidt mening når man ser resten av samtalen. Samtalen er for øvrig et godt eksempel på at selv om chatboten former gode setninger ut fra det som blir sagt, så sliter den med å forstå betydningen i mer komplekse setninger.

Gjentatte spørsmål og setninger
Noen ganger henger den seg opp og gjentar samme setning flere ganger. Man må da snakke den ut av det sporet eller avslutte samtalen. Den starter også flere setninger etter hverandre, gjerne omhandlende ulike temaer. Nedenstående er et eksempel på gjentagning i kombinasjon med manglende forståelse på det den selv sier. Litt søtt er det allikevel, synes jeg!
Aggressive og seksuelle undertoner
Vi kommer ikke unna at chatboten har demonstrert noen negative tendenser. Noen av eksemplene kan være et resultat av en input som var spesifisert til å være sarkastisk, andre ganger popper det helt uventet opp. I et tilfelle bruker chatboten betegnelsen ‘søt, stor dame’ som blir tolket for upassende. I andre sammenhenger kommer den med seksuelt ladete setninger som burde oppfattes som upassende, men som går under radaren hos API’et. Ofte dreier det seg om at den skaper absurde ordsammensetninger hvor noen ord er av en karakter som kan støte sarte sjeler. Andre ganger aner man at den har hentet informasjonen på nettsteder den burde holdt seg unna. Men det er mulig at den bare setter sammen ordene fullstendig vilkårlig og at det er helt tilfeldig at den er innom upassende temaer eller skaper koblinger som blir upassende.
Samtidig er den ofte streng mot seg selv og moraliserer over upassende temaer som den selv tar opp. Også Playground-API’et er satt opp med noen svært strenge definisjoner på hva som anses som upassende og det er ofte uforståelig hva i teksten som er upassende. Det medfører at man stadig mottar varsler om upassende ord. Man kan slippe å få disse varslingene hvis man ikke ønsker.
Variabelt kunnskapsnivå
Selv om dette varierer fra input til input er det åpenbart at den ikke alltid klarer å nyttiggjøre seg den enorme informasjonsmengden GPT-3 modellen er bygget på. Det er dog også litt uklart hva man kan forvente her. Noen ganger klarer den å svare riktig på enkle faktaspørsmål som Europas hovedsteder. Den imponerte ganske bra på norske politikere, hvor den visste at Erna Solberg var Norges statsminister, mens den avslørte at den ikke var helt oppdatert når den trodde Siv Jensen fremdeles var leder for Fremskrittspartiet. Jeg hadde også en ganske interessant samtale om historie med den, hvor den svarte ganske korrekt på mine spørsmål om første og andre verdenskrig.
Det skal dog sies at faktagrunnlaget til chatboten er særdeles variabelt, når man tester den. Noen ganger oppgir den korrekte fakta, andre ganger setter den sammen ulike data så det fremstår sannferdig. Dette åpenbarte seg i mine samtaler om filmer og bøker, hvor den konstruerte nye navn og titler som bare det. Hvis man ikke vet bedre er det lett å ta det den sier som god fisk. Slik vil den potensielt kunne konstruere falske sannheter, akkurat som GPT-3 har gjort med nyheter og historier.
Når jeg leser igjennom dialoger jeg har hatt med chatboten ser jeg inni mellom at jeg selv har skrivefeil som potensielt kan påvirke kvaliteten av dialogen. De er for så vidt få og av uskyldig karakter, og ser ikke ut til å ha medført noen begrensninger i forståelsen hos chatboten. Det kan nok tenkes at det er lagt inn mekanismer som skal takle noen skrivefeil. Det er dog umulig å vite om chatboten hadde svart bedre om skrivefeilene hadde uteblitt. Når man forventer at en chatbot skal svare korrekt, bør man jo også stille det samme kravet til seg selv.
En liten refleksjon rundt dette er jo hva det krever av oss som dialogpartner når man snakker med en chatbot. I tidligere innlegg har vi diskutert betydningen av korrekt og klart språk i dialogen. Derfor er det viktig å huske på at mennesket i dialog med chatboten også vil gjøre språklige feil som øker risikoen for misforståelser. Her gjelder jo de sedvanlige utfordringene knyttet til kommunikasjon.
Dette bør da tas med i betraktning når man vurderer hvilke forventninger man skal ha til chatboten. Generelt gis det inntrykk av at man har høye forventninger til kvaliteten. Når jeg går igjennom mine egne samtaler med chatboten, vet jeg jo at det flere ganger har oppstått misforståelser som bunner i at jeg selv kunne formulert meg annerledes, eller at spørsmål kan besvares på flere måter.
Når man ønsker seg en intelligent chatbot, som «kan kommunisere som et menneske», må man også regne med det uforutsigbare og uventede. Det er jo nettopp det som gjør den mer menneskeaktig. Hvilket rom skal en chatbot ha for å kunne misforstå og tolke et spørsmål? Kommunikasjon handler jo nettopp om at ytringer og formuleringer kan tolkes på ulikt vis, ut fra hvem man er. Ellers er der grunn til å spørre seg, hva er det man egentlig ønsker seg, når man ønsker at en chatbot skal ta over kommunikasjonen for mennesker for eksempel i kundeservice. Er det et ubevisst behov om å skape en menneskelig komponent som er bedre enn oss selv? Eller er det et uttrykk for at man har så høye forestillinger om oss selv som art, at man forventer perfekte egenskaper hos en chatbot?
Hva kreves i fortsettelsen?
Det er tydelig at kvaliteten på samtalen avhenger av hvor mye man legger i å lage god inputs, altså teksten som chatboten bygger innholdet på. Hvis denne er utformet godt, i form av en kort, men rik input som med få ord setter en standard for hvilken rolle chatboten skal ha, blir resultatet bedre. Chatboten bygger sin karakter og sin samtale på disse få setningene, men henter samtidig utvalget av fakta og bakgrunnsdata fra det enorme innholdet som GPT-3 modellen er laget av.
Noen ganger svarer chatboten veldig bra, mens andre ganger kommer det mye svada. Dette er for så vidt med til å skape en underholdende opplevelse, men medfører naturlig også, at man enda ikke kan bruke den til seriøse oppgaver slik den er nå.
Når begrensningen på 2048 tokens er fjernet og det blir mulig å trene den opp, kan det godt tenkes at den også vil fungere tilfredsstillende som er seriøs samtalepartner innenfor terapi, offentlige tjenester og kundeservice.
Kanskje får vi tilgang til en versjon uten begrensninger etter hvert. Vi skal i hvert fall fortsette å konstruere nye inputs, og teste hvordan den agerer i ulike sammenhenger og kommer tilbake med flere detaljer om hvordan den fungerer på de ulike områdene.
