
Den største språkmodellen som finnes i dag er GPT-3. Den ble lansert av OpenAI i fjor, og imponerte en hel verden av AI-interesserte med sine evner til å løse ulike NLP-oppgaver. Modellen er basert på samme arkitektur som sin forgjenger GPT-2, men med 175 milliarder parametere er den mer enn hundre ganger så stor. Den er også trent på et langt større datasett. Dette har vist seg å øke prestasjonen betraktelig. Det har også introdusert konseptet prompt programmering innen NLP. Hva betyr egentlig dette for oss?

Først litt bakgrunn: GPT står for Generative Pretrained Transformer. Det refererer til at dette er en generativ modell med Transformers-arkitektur. Det refererer også til at den er forhåndstrent (pretrained). Det vil si at modellen er trent på en stor mengde data for generell språkforståelse, og at den kan finjusteres på ulike NLP-oppgaver. Arkitekturen til modellen er med andre ord oppgaveagnostisk, men modellen videretrenes på datasett spesifikt for oppgaven den skal løse. Dette er en metode flere store modeller har basert seg på, blant annet BERT.
Det er imidlertid et par ulemper med denne metoden. For det første kreves det fremdeles store datasett tilpasset NLP-oppgaven den skal løse. For det andre vil denne finjusteringen medføre at modellen blir mindre generell, og presterer dårligere på data som ikke likner treningsdataen.
Dessuten, mennesker trenger ikke tusenvis av eksempler for å forstå en oppgave. Det holder stort sett med en enkel forklaring av oppgaven, og kanskje et par eksempler, så er vi i gang. Spørsmålet blir dermed: Kan en språkmodell klare det samme?
Og ja, det ser faktisk slik ut!
I GPT-3-artikkelen kaller de denne formen for «læring» (altså uten at man finjusterer modellen eller oppdaterer noen av parameterne) in-context learning. Modellen skal forstå oppgaven ut ifra konteksten den blir gitt som input. De illustrerer også effekten av å øke størrelsen på modellen for å få dette til:
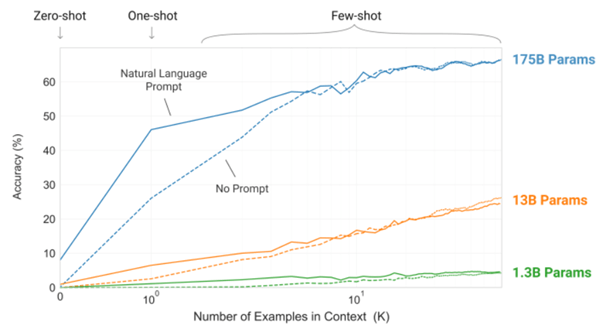
Ut ifra denne grafen er det tydelig at størrelse er essensielt for å mestre in-context learning. Men hvordan presterer den i forhold til modeller som er finjustert på spesifikke NLP-oppgaver?
Ifølge GPT-3-artikkelen: stort sett bra! På mange oppgaver presterer GPT-3 nærme eller bedre enn state-of-the-art.
Ifølge senere testing: enda bedre! Det har vist seg at GPT-3 presterer langt bedre enn først antatt på noen oppgaver kun ved å få bedre eksempler og en god beskrivelse. Slik god prompting har vist seg å være så viktig at noen nå kaller dette en ny type programmering, prompt programmering.
Og at GPT-3 har behov for slik språklig kontekst er ifølge denne analysen ganske naturlig. Husk at GPT-3 settes i gang kun med å få en tekstlig beskrivelse og eksempler på oppgaven den skal løse. Uansett om oppgaven er tekstklassifisering, tekstgenerering, intentanalyse, chat, poesi, spørsmål/svar, summering osv. Jo bedre forklaring, jo bedre utgangspunkt har modellen for å prestere. Sånn er det jo også for mennesker!
Et meget interessant eksempel i den sammenheng er hvordan GPT-3 håndterer meningsløse spørsmål. I stedet for å svare «det vet jeg ikke» eller «det gir ikke mening», kan den finne på å svare like tullete tilbake. Se eksempelet fra en twitterbruker under:

Dette har blitt brukt som argument for at den ikke klarer å skille mellom mening og tøys. Men er det heller et argument for at spørsmålet i utgangspunktet var ganske tøysete? Under er samme eksempel med bedre prompting (alt i kursiv er brukerens input/prompt):

GPT-3 har jo faktisk ingen problemer med å skjønne hva som gir mening. Den må bare vite at det er mening vi er ute etter.
Utfordringer
Nå skal det nevnes at GPT-3 ikke er helt uten utfordringer. Blant annet er sampling et viktig element i interaksjon med språkmodeller. Dette dreier seg om hvordan man predikerer neste ord, for eksempel om modellen velger mellom de topp 3 mest sannsynlige ordene eller topp 20. Akkurat hva slags sampling som fungerer best til ulike oppgaver er vanskelig å vite, og må ofte bare testes. Et sampling-problem man heller ikke har funnet en god løsning på er at språkmodeller – også GPT-3 – har en tendens til å repetere seg selv.
En annen utfordring er hvordan språkmodeller generelt leser språk. De ser tekst i form av ord eller delord, såkalte tokens. GPT-3 har altså ikke forutsetning for å forstå så mye på karakternivå. Dette er mest sannsynlig årsaken til at den ikke er så god på for eksempel riming eller puns.
Enda en utfordring er lengden på input. Maks lengde er 2048 tokens. Den kan altså ikke se noe lenger enn akkurat de 500-1000 ordene dette tilsvarer. Det gjør det vanskelig for den å generere lange tekster uten å miste sammenheng. Det gjør det også vanskelig med in-context learning i tilfeller der det er nødvendig med mange eksempler, i og med at promptet/inputen er en del av disse 2048 tokens.
Prompt programmering – veien å gå videre?
Det er ingen tvil om at nyere og større språkmodeller har ført til endringer både i prestasjon og i metodikk. I stedet for å videretrene modeller på store datasett for å klare spesifikke oppgaver, kan man nå ganske enkelt snakke med den og fortelle den hva den skal gjøre. Begynner vi rett og slett å nærme oss språkmodeller som likner på oss mennesker?
I vårt chatbot-prosjekt har vi testet både å bygge opp et eget nevralt nettverk for NLP, videretrene en liten dialogspesifikk språkmodell og å videretrene en generell språkmodell. Vi har opplevd at vi har kommet et lite steg lenger hver gang. Steget opp til å teste GPT-3 har imidlertid føltes mer som å reise til månen i forhold.
Derfor er det ganske naturlig at vårt prosjekt tar en ny retning, der GPT-3 (eller eventuelt fremtidige språkmodeller) utgjør grunnlaget, og at vi legger fokuset på prompt programmering. Fra det vi allerede har testet (også på norsk!) ser dette veldig lovende ut!
