
Arbeidet med vennen.ai er til tider utfordrende. Som jeg har kommet inn på i tidligere innlegg, å utvikle en chatbot som kan holde en god dialog er ikke lett. Christina og jeg har kommet litt lengre på veien, men ettersom prosjektet er såpass komplekst har jeg prøvd meg på mindre sideprosjekter og mer konkrete oppgaver inne NLP (Natural Language Processing).

En problemstilling ute hos mange bedrifter er at de mottar store mengder med henvendelser fra kunder. Dette kan være hyggelige meldinger som ros, eller det kan være sinte klager. Disse kan kundebehandlere bruke mye tid på å komme seg igjennom. En maskinlæringsmodell kan være behjelpelige med å sortere eller behandle lettere saker på vegne av saksbehandlerne. Slik sparer bedriften tid og penger. Og saksbehandlerne kan prioritere de sakene som er viktigst.
En populær NLP-relatert oppgave for tiden er noe som kalles sentimentanalyse. Det går ut på å fange opp stemningen i en tekst. Det kan for eksempel være en filmanmeldelse, en kundeklage eller et input til en chatbot. Jobben til en modell blir å plassere teksten i korrekt klasse. Disse klassene kan være terningkast eller en positive/negative-kategori. En sentimentmodell kan fange opp sinte meldinger fra kunder slik at disse blir prioritert og håndtert raskt. Eller den kan hjelpe en chatbot med å forstå innholdet i et brukerinput. Er brukeren sint eller glad.

Fordelen med en slik oppgave er at den er lett definerbar og verifiserbar. Det er mulig å si noe konkret om hvor godt en slik modell fungerer ut fra statistikk og analyse. I motsetning til utvikling av en chatbot der utfordringene er mange, men et av de mer krevende er å teste og verifisere. Dette er noe jeg kan komme mer tilbake til i et senere innlegg.
Dette betyr ikke at sentimentanalyse ikke har sine utfordringer. Noe jeg er blitt smertelig klar over i prosessen. Når det gjelder å løse oppgaver innen norsk språk er ressursene sparsomme. Mangel på gode ordlister, datasett og andre hjelpemiddel gjør noen ganger jobben mer utfordrende enn den allerede er. Jobber man med engelsk derimot, er utvalget langt større. Men NLP er et voksende felt i Norge, og stadig kommer det mer verktøy i verktøykassa. Nasjonalbiblioteket og de store universitetene jobber mye på feltet [1], [2].
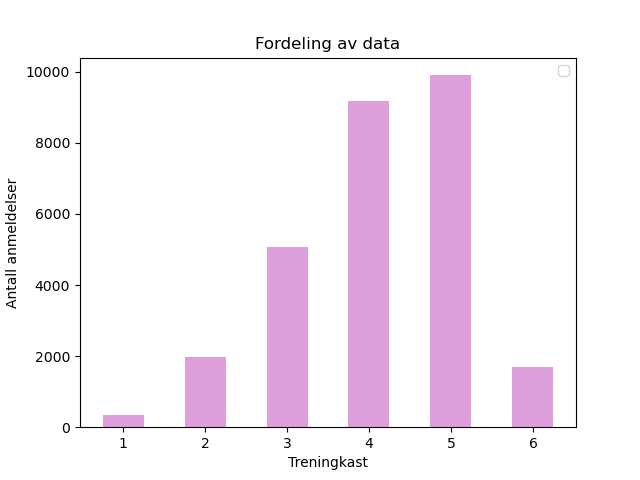
Et annet og mulig større problem, som for så vidt er gjennomgående når det gjelder ML, er ubalanserte datasett. Virkeligheten er jo gjerne ubalanserte. Filmanmeldere har en tendens til å gi flere firere og femmere enn de gir terningkast 1 eller 6. Ettersom dette er et hyppig problem innen ML finnes det også mange mulige løsninger på ubalanserte dataset. En enkel løsning er under-sampling, altså at man velger ut den kategorien med færrest datapunkter og nedjusterer datamengden til de andre kategoriene slik at alle er like store, eller like små, alt ettersom man velger å se på ting. En ulempe med under-sampling er at man mister mye data.
Andre løsninger er over-sampling, det vil si at man velger å bruke en mengde med data fra datasettet mer enn en gang. Dette fører fort til at man overfitter modellen til denne dataen. Men dette kan fikses med f.eks. k-fold cross-validation [3] som vil si at man i praksis lager mange mindre modeller basert på flere tilfeldige utvelgelser av databolker fra datasettet. Deretter kan man ta et gjennomsnitt av alle modellene man har laget. En annen løsning er å vekte kategoriene ulikt under trening. Det vil si at man velger å legge mer vekt på de underrepresenterte klassene enn de som er overrepresenterte.
Det at datasettet jeg bruker kommer med terningkast mellom 1 – 6, altså 6 mulige kategorier, gjør problemstillingen noe komplisert. Det kan være vanskelig, om ikke umulig, for et menneske å skulle vurdere en anmeldelse og så gjette hvilket terningkast den er satt til. Da er ikke dette trivielt for en ML-modell heller. Dermed må problemstillingen forenkles. Dette gjøres ved å kutte ned på antall klasser, altså slå sammen klasser. Dette løser flere problemer. Ved å slå sammen kategorier øker man størrelsen på datamengden til den underrepresentert klassen ved undersampling. I tillegg vil treningen fungere mer optimalt da et problem som dukker opp ved sentimentklassifisering er at, dersom den korrekte labelen er terningkast 5 og modellen predikerer terningkast 6, vil modellen bli straffet like mye som om den predikerte terningkast 1. Dette blir feil, da terningkast 6 jo er nærmere 5 enn det 1 er.
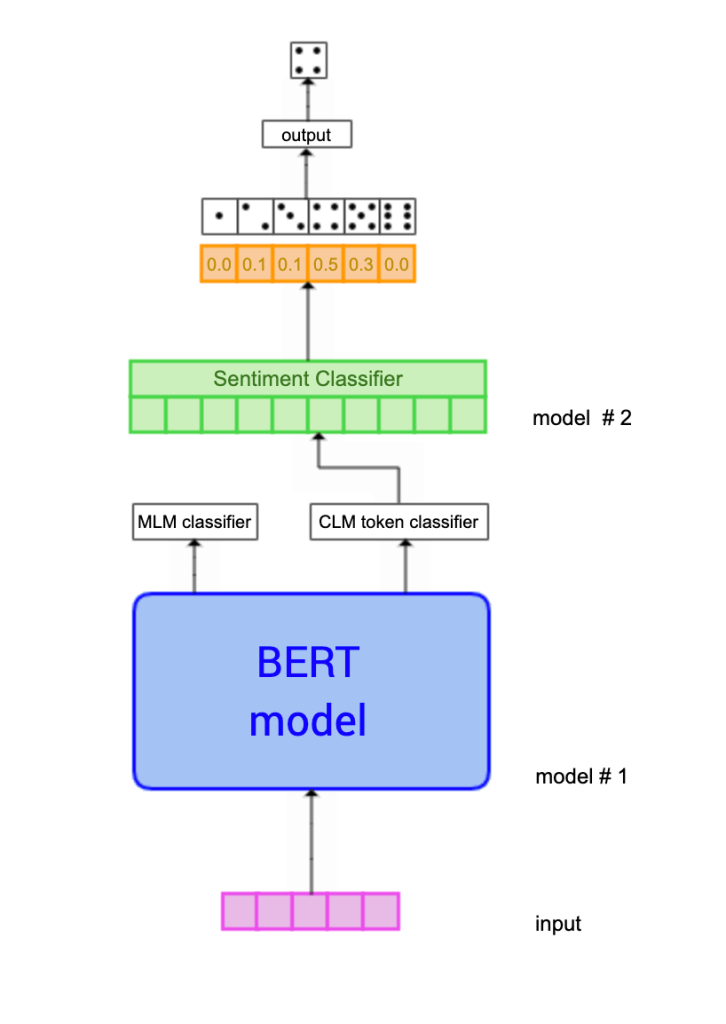
Et oppsett av modellen jeg bruker kan ses i figuren over. Den tokeniserte teksten, input-vektoren, går direkte inn til Bert. Det vil si den behandlede teksten representert i form av tall, slik at modellen skal kunne tolke input.
Bert har to outputs, alt ettersom modelltypen1) man bruker og hvordan man har konfigurert. Men hovedsaklig er det et Masked-Language-Modeling output og et Causal-Language-Modeling output. MLM er til videre trening på det å maskere ord for så å la Bert predikere disse. CLM er en mer allsidig classifier da denne gir et output på formen [batch_size, hidden_states], hvor batch_size er antall batches i input og hidden_states er størrelsen på det siste skjulte laget (hidden layer) fra den siste Transformer block i Bert, som er på 768 noder. Dette er ikke viktig å forstå, det som er viktig er at CLM-output kan sendes inn til en separat classifier som jeg har valgt å kalle en egen modell i figuren over, med ett lag på 768 noder.
Denne classifieren skal da prøve å skjønne en sammenheng mellom anmeldelsesteksten og terningkastene, helst da ved å se en sammenheng mellom stemning i teksten og terningkast. Dette er ikke trivielt, men tanken er at en god språkmodell i bunn kanskje kan være behjelpelig. Lineær-laget gjør en lineærtransformasjon på innputtet fra Bert, og konverterer det til et lag som inneholder like mange punkter som antall klasser vi ønsker å klassifisere.
Den siste biten i treningsprosessen blir da å regne ut loss, eller hvor rett eller galt modellen har gjettet. Dette kan gjøres med bruk av en Cross Entropy Loss-funksjon2). Det denne funksjonene gjør er å fremstille output fra linear classifier som en sannsynlighetsdistribusjon som kan sammenlignes med den korrekte sannsynlighetsdistribusjonen, eller det korrekte terningkastet om du vil. Korreksjon av parametrene i modellene blir justert basert på dette losset, og er måten modellen lærer på.
Som en kuriositet gjorde jeg en simpel ordtelling på deler av datasettet, som en test på om en enkel analyse ville si noe om forholdet mellom innholdet i tekstene og terningkastet. Dette var hovedsakelig fordi jeg ikke fikk modellen til å fungere som jeg ville i starten. Det jeg gjorde var simpelthen å telle antall positive og negative ord i teksten. Jeg fant to ordliste på nett som inneholdt negative og positive ord. Resultatet kan sees i figuren under.

Figuren viser antallet positive ord i blått og antall negative ord i rødt fordelt på terningkast. De positive datapunktene ser ut til å gi mening, for økende terningkast øker også antall positive ord i anmeldelsen. Men det samme gjør antallet negative ord. Som jo intuitivt burde være motsatt. Jo bedre anmeldelse, jo færre negative ord. Men en slik analyse lider av flere utfordringer. For det første er det dårlig tilgang på gode ordlister på norsk. For det andre klarer ikke en så enkel modell å skille mellom ironi og sarkasme og en positiv tekst.
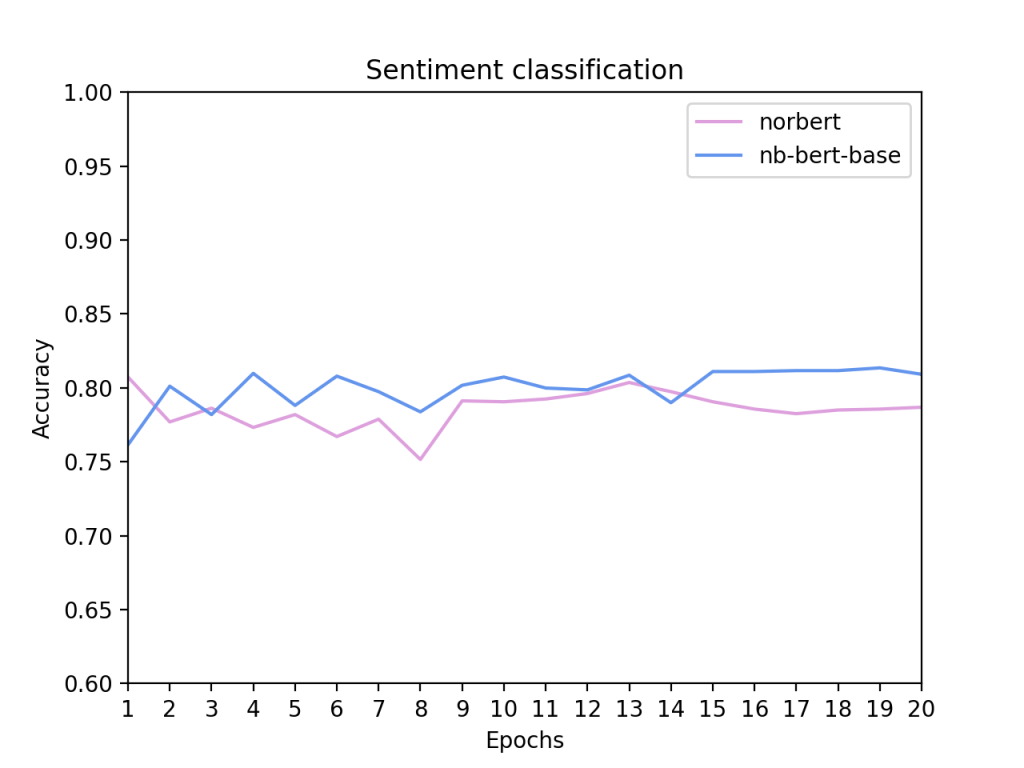
Så hvordan fungerer Bert til å gjøre sentimentanalyse? Svaret er at den fungerer relativt bra. I figuren under er treningsprogresjonen for to norske Bert-modeller som ligger tilgjengelig hos Huggingface. Den ene heter Norbert og er UiO sin modell, den andre er Nasjonalbiblioteket sin. Begge modellene scorer ganske høyt på nøyaktighet, de klarer predikere 80% av datasettet under evaluering til korrekt kategori. Dette er ganske bra.
Men hvis vi ser tilbake på bruksområdene til en slik analyse, kan en slik modell fungere på kundehenvendelser eller en chatbot? Stemningen i en filmanmeldelse kan se veldig ulik ut fra en melding fra en bruker av en chatbot. Så hvordan fungerer sentimentmodellen på slik input? Jeg lagde et lite skript på sinte og glade meldinger. Meldingene var av typen: “Hvorfor er du så dum? Du skjønner jo ikke noen ting”, “Din dumme chatbot” og “Kake er det beste som finnes, det er utrolig godt” og labelet de som kategori positiv og negativ. Under er resultatet!
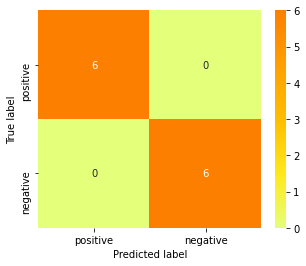
Alle positive datapunkter blir kategorisert som positive og alle negative datapunkt blir kategorisert som negative. Strålende! Denne sentimentmodellen kunne nok blitt brukt til å hjelpe en chatbot i å vurdere brukerens sinnsstemning.
1) Bert kan brukes til mange ulike problemstillinger. Det finnes en enkel BertModel, som er hovedmodellen, men også modeller som egner seg til sekvensmodellering eller spørsmål-og-svar modellering.
2) Dette er i PyTorch en kombinasjon av Softmax og Negative-Log Likelihood.
Kilder:
[1] Kutuzov, A., Barnes, J., Velldal, E., Øvrelid, L., & Oepen, S. (2021). Large-Scale Contextualised Language Modelling for Norwegian. arXiv preprint arXiv:2104.06546. Hentet fra: https://arxiv.org/abs/2104.06546
[2] Kummervold, P. E., De la Rosa, J., Wetjen, F., & Brygfjeld, S. A. (2021). Operationalizing a National Digital Library: The Case for a Norwegian Transformer Model. arXiv preprint arXiv:2104.09617. Hentet fra: https://arxiv.org/abs/2104.09617
[3] Krishni. (2021, 5. mai). K-Fold Cross Validation. Medium – Data Driven Investor. https://medium.datadriveninvestor.com/k-fold-cross-validation-6b8518070833
Alammar, J. (2021, 5. mai). A Visual Guide to Using BERT for the First Time. Jay Alammar. Visualizing machine learning one concept at a time. https://jalammar.github.io/a-visual-guide-to-using-bert-for-the-first-time/
