
Nevrale nettverk finner man i dag nærmest overalt. Bruker du ansiktsgjenkjenning for å låse opp telefonen din? Nevralt nettverk. Fingeravtrykkleser? Nevralt nettverk. Ordforslag på tastaturet? Også et nevralt nettverk. For ikke å nevne talegjenkjenning, selvkjørende biler, personlige assistenter og brukertilpasset reklame. De bruker alle ulike typer nevrale nettverk. Og det er nettopp et slikt nevralt nettverk vi benytter for å lage vår chatbot.
Men hva er egentlig et nevralt nettverk?
Kort forklart er det et forsøk på å imitere hjernen. Den menneskelige hjernen består av milliarder av nevroner som samhandler for å lære, forstå og tolke informasjon. Dette forsøkes gjenskapt i en datamaskin gjennom lag på lag med parametere. I de nevrale nettverkenes tilfelle består disse parameterne av tall.
Til å begynne med er disse tallene gjerne helt tilfeldige. For at de skal gi noen mening, må de derfor trenes. Da sendes det inn en input som går gjennom alle lagene i nettverket og resulterer i en prediksjon. Denne prediksjonen vurderes mot en fasit, og gapet mellom dem kjøres deretter tilbake gjennom nettverket og brukes til å oppdatere parameterne.
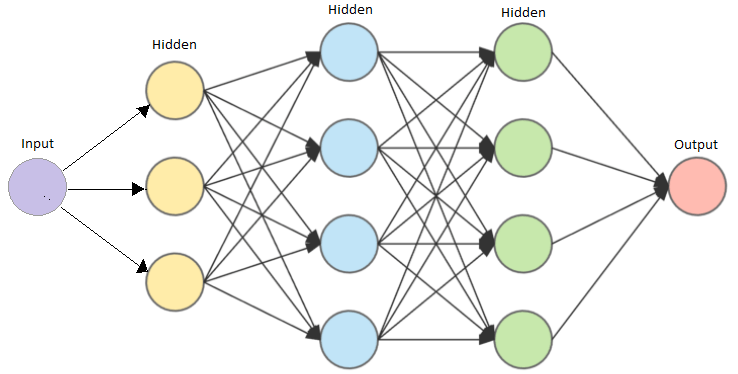
Under ser du en representasjon av disse lagene. Det er i hovedsak tre typer: Første lag er inputen man sender inn i nettverket, så kommer såkalte hidden layers (skjulte lag) som gjør alle beregningene, og til slutt et output-lag.
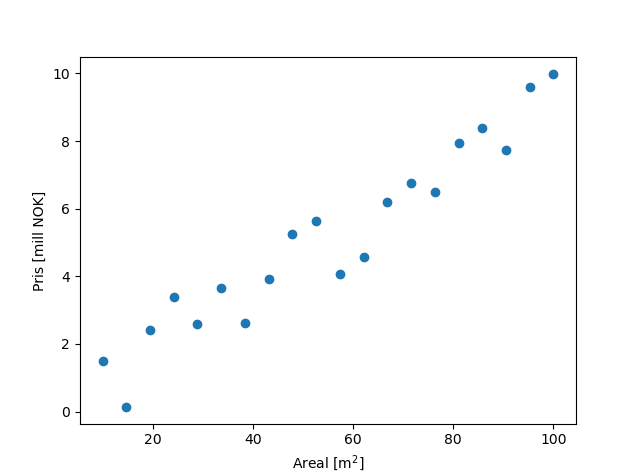
Inputen som sendes inn i nettverket kan være en hvilken som helst informasjonsmengde. Dersom det er en korrelasjon mellom noen variabler i datamengden, vil nettverket oppdage dette. Det kan så benyttes til å forutsi resultatet av ny data. Et enkelt eksempel er å se på boligpriser ut ifra størrelse på boligen. Under har jeg laget et plott med areal på x-aksen og pris på y-aksen. Vi kan (i dette meget forenklede plottet) se en tydelig sammenheng.
Si jeg nå ønsker å kjøpe en bolig på 50 kvadrat. Hva kan jeg da forvente av pris? Kan jeg bruke tidligere data til å finne ut av dette?
Ja!
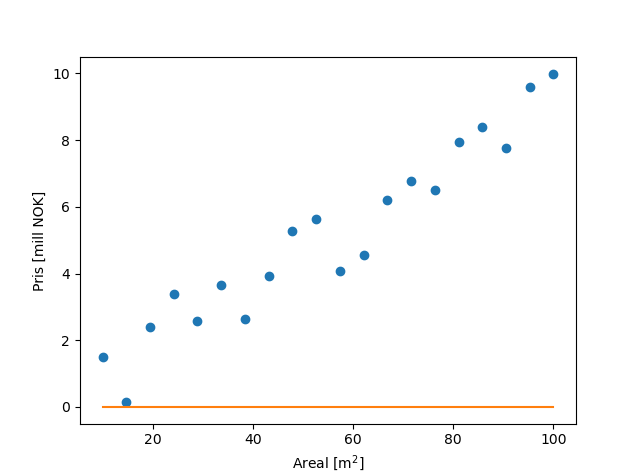
Et nevralt nettverk er laget akkurat for slike problemstillinger. Den trener på en type datasett, og kan deretter kjenne igjen liknende data og gi en prediksjon. I vårt tilfelle kan vi nå sende inn historiske data på boligpris og areal. Til å begynne med lar vi alle parameterne i nettverket være 0. Da vil vår prediksjon (den oransje linjen) se slik ut:
Så starter vi treningen. Etter den har sett en del data, vil nettverket begynne å nærme seg:
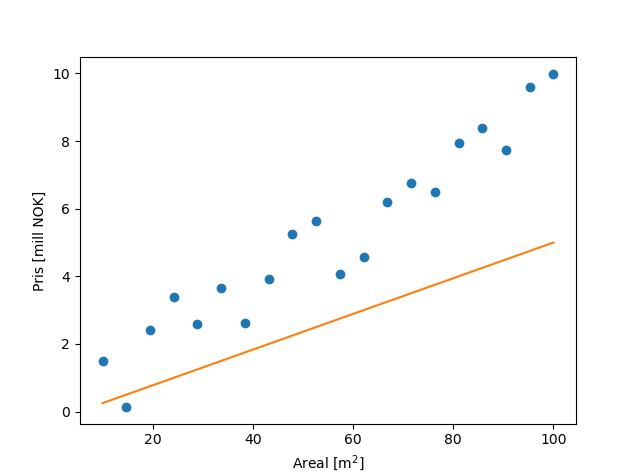
Så, når treningen er over, vil resultatet se slik ut:
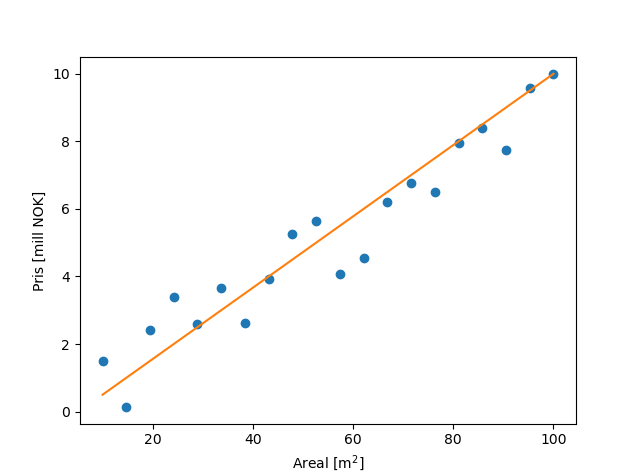
Nå kan du bare sende inn ønsket areal og få prisen i fanget!
Nå er det som oftest ikke slik at realistiske datamengder kun avhenger av én variabel. Det er gjerne flere faktorer som spiller inn. I vårt eksempel kan det jo blant annet nevnes type bolig, byggeår, område og fasiliteter.
Nettverket presentert over er som du nå skjønner et veldig simpelt nettverk. For å ta hensyn til flere faktorer kan man blant annet legge til flere lag. Man kan også endre antall parametere i lagene, og variere hva slags kobling det er mellom dem. Det er også vanlig å benytte ulike aktiveringsfunksjoner mellom lagene. Dessuten kan man bestemme hvor mye parameterne kan endres under trening, og om det er noen verdier som bør tas ekstra hensyn til. Treningsdatasettet kan også tilpasses for å øke presisjonen.
Å finne den perfekte kombinasjonen er med andre ord en kunst. Det er vanskelig å si noe om hva som fungerer best uten å teste.
En litt mer komplisert oppgave er bildegjenkjenning. Man kan for eksempel ha et treningsdatasett med masse bilder av hunder og katter, og trene nettverket opp til å se forskjellen. Inputen er nå flerdimensjonal (størrelsen på bildet), og fasiten er sannsynligheten for at det er en hund eller en katt. I slike nettverk trenes lagene opp til å finne features (egenskaper) som rette linjer, skarpe kontraster, buede former eller spesielle fasonger. Kombinasjonen av dette vil så bestemme hva outputen blir. Under ser dere et eksempel på et slikt nettverk:

I vårt prosjekt driver vi med Natural Language Processing (NLP) – maskinlæring innen språk. Ideen går ut på det samme – at du har flere lag med parametere som trenes – men til forskjell fra et nettverk som finner egenskaper i et bilde, er nettverket her konstruert for å behandle data i sekvenser (setninger).
En utfordring med NLP er at vi jobber med ord og bokstaver i stedet for tall. Nevrale nettverk leser kun siffer, og man må derfor finne en måte å representere språket på med tall. Løsningen er å forhåndsprosessere dataen med det man kaller tokenisering. Man kan da tilegne ord eller delord spesifikke tall, som så utgjør et «ord-rom». I denne prosessen er det flere ting som skjer, blant annet vil ord som likner eller har samme betydning ligge nærme hverandre i ord-rommet. Ulike mekanismer vil også se på hvilke ord som har mest betydning i en setning, for så å huske dette videre i neste prediksjon.
Sammenliknet med å skille mellom hunder og katter, eller predikere boligpris basert på areal, er dette ganske komplisert. Selv en relativt enkel NLP-oppgave som å skille mellom positive og negative anmeldelser krever et ganske stort nettverk og store mengder treningsdata. I vårt tilfelle ønsker vi dessuten ikke bare å klassifisere tekst, men å generere setninger. (Se gjerne tidligere innlegg for utfordringene knyttet til dialog). Dette er et område som det forskes mye på, og store selskaper som Google, Microsoft og OpenAI kommer stadig med nye metoder, og større og mer imponerende modeller. Spesielt sistnevnte sin GPT3 som dukket opp i fjor har imponert NLP-interesserte verden over med sin evne til å løse ulike NLP-oppgaver. Som nevnt i et tidligere innlegg håper vi på å dra nytte av dette, og har allerede fått testet litt hva den nye norske BERT-modellen kan gjøre!
Dette var altså en kort introduksjon til nevrale nettverk og NLP. Vi er midt i en spennende epoke der utviklingen skjer raskt, og fremskritt gjøres både innen metode, bruksområder og størrelse på nettverkene. Så selv om prosjektet vårt er meget ambisiøst, har vi tro på at dette kan la seg gjøre, og ikke minst at vi lærer masse underveis i prosessen!
