
Hvordan kan en maskin forstå hva et menneske sier til den? Og hvordan kan den svare? Dette er spørsmål vi jobber med her på Innovatec, og som vi ønsker å finne gode løsninger på.
Problemet kan brytes ned i tre deler:
- Speech To Text (STT)
- Natural Language Processing (NLP)
- Text To Speech (TTS)
Det handler altså først om å konvertere tale til tekst (STT), deretter tolke teksten og generere et svar med NLP, og til slutt konvertere tekst til tale (TTS). Les gjerne tidligere blogginnlegg om NLP! Min oppgave har vært å sette meg inn i STT og se hvordan vi kan skape vår egen tale-til-tekst-maskin.
Representasjon av lyddataen
Det er tre viktige komponenter som utgjør en STT-motor: representasjon av data, en akustisk modell og en språkmodell. Representasjon av data dreier seg om å gi modellen input i et format den klarer å forstå. For NLP-modeller dreier dette seg om å konvertere ord og bokstaver til tall. For lyd kan dataene representeres ved å lage et spektrogram.
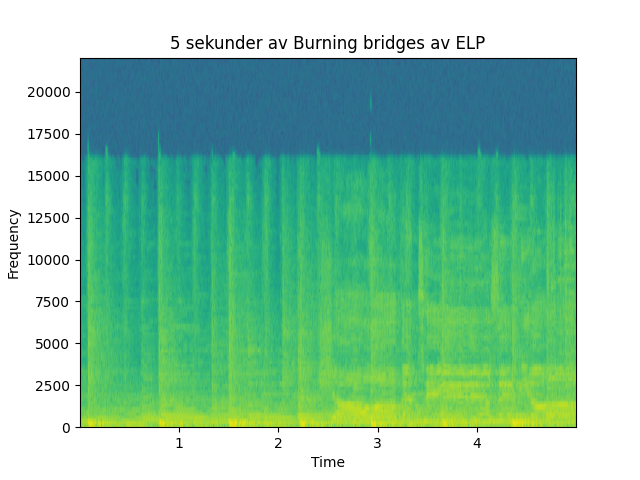
Et spektrogram er en representasjon av styrken til lydfrekvenser i et gitt tidsintervall og hvordan det forandrer seg over tid. Frekvensene blir beregnet gjennom en fouriertransformasjon av lyddataene. Denne prosessen er det man gjerne kaller preprosessering av inndata.
Akustisk modell
Oppgaven til den akustiske modellen er å konvertere lyddata til tekst. Dette er det knyttet en del utfordringer til, og er nok den vanskeligste delen med STT.
Det finnes flere måter å bygge en akustisk modell på. Tidligere var hidden markov modeller svært populære, men de senere årene har man sett at dype nevrale nettverk gir bedre resultater. Et prosjekt som har brukt et slikt nettverk for sin akustiske modell er Baidu Research sin «Deep Speech 2». Modellen tar en representasjon av lyddataen (spektrogram), leser av hvert intervall og avgjør hvilken bokstav som mest sannsynlig blir sagt i det intervallet.
En av utfordringene den akustiske modellen må håndtere er lengden på en ytring. Mennesker snakker med forskjellige hastigheter, så outputen til modellen vil ikke nødvendigvis ha samme lengde som setningen som blir sagt. Ordet «hallo» kan for eksempel ende opp med å se slik ut: «hhaa-lll-lloooo». Dette kan løses ved å bruke en såkalt skvisefunksjon, CTC (Connectionist Temporal Classification). Denne funksjonen vil først fjerne like bokstaver som kommer rett etter hverandre. Vi vil da få «ha-l-lo». Deretter kvitter den seg med de blanke bokstavene og ender opp med «hallo».
En av de største fordelene ved å bruke et dypt nevralt nettverk er at man ikke trenger å gjøre forandringer på modellen for å lære modellen et nytt språk. Det en slik modell derimot trenger er masse data. Og akkurat det kan by på utfordringer, spesielt for et lite land som Norge med begrensede mengder norsk data.
Språkmodell
Utfordringen med mengden data er ekstra problematisk innen talegjenkjenning, fordi vi tilsynelatende både trenger lyddata og tilhørende transkripsjon. Modellen bør jo ha en fasit den kan lære av. Dette kan virke nærmest håpløst, men heldigvis finnes det en løsning: Vi kan benytte en språkmodell! Disse trenes opp kun på tekst, så da trenger vi ikke nødvendigvis transkripsjoner av lyddataen likevel.
Hensikten til en språkmodell i vårt tilfelle er å regne ut sannsynligheten for en gitt sekvens av ord. Nå som vi har fått ord og setninger av den akustiske modellen, kan vi bestemme om dette er en setning noen faktisk ville ha sagt. En enkel modell man kan bruke er en N-gram-modell. Dette er en språkmodell som på en nokså primitiv måte lærer seg grammatikk, og kan være med på å minimere feil i tolkningen av en setning som blir sagt. La oss se på to setninger som likner på hverandre:
Vi skal lage pepperkaker.
Vi skal lage pepper hager.
Mennesker kan enkelt se at den første setningen gir mer mening enn den andre, men det gjør ikke den akustiske modellen. Det er rett og slett ikke dens oppgave. En språkmodell derimot vil oppdage forskjellen, og ved å bruke begge deler kan man øke sannsynligheten for at STT-motoren gir et svar som gir mening.
Konklusjon
Vi har nå gått gjennom komponentene som utgjør en STT-motor (representasjon av data, akustisk modell og språkmodell), og funnet løsninger på noen av utfordringene ved talegjenkjenning. Dette er blant annet ved å bruke CTC-funksjonen til å bli kvitt avhengigheten av lengden på dataen, og å bruke en språkmodell sammen med den akustiske modellen for å få mer meningsfylte setninger. En av de største utfordringene jeg tror vi kommer til å støte på fremover er å få tak i nok treningsdata.
Dette har vært et spennende og lærerikt prosjekt, og jeg ser fram til å fortsette arbeidet fremover!
Les mer:
Amodei, D., Anubhai, R., Battenberg, E., Case, C., Casper, J., Catanzaro, B., Chen, J., Chrzanowski, M., Coates, A., Diamos, G., Elsen, E., Engel, J., Fan, L., Fougner, C., Han, T., Hannun, A., Jun, B., LeGresley, P., Lin, L., Narang, S., Ng, A., Ozair, S., Prenger, R., Raiman, J., Satheesh, S., Seetapun, D., Sengupta, S., Wang, Y., Wang, Z., Wang, C., Xiao, B., Yogatama, D., Zhan, J. and Zhu, Z., 2021. Deep Speech 2: End-To-End Speech Recognition In English And Mandarin. [online] arXiv.org. Available at: <https://arxiv.org/abs/1512.02595> [Accessed 6 January 2021].
Brownlee, J., 2019. What Is Deep Learning?. [online] Machine Learning Mastery. Available at: <https://machinelearningmastery.com/what-is-deep-learning/> [Accessed 6 January 2021].
Jurafsky, D. and Martin, J., 2020. Speech And Language Processing. [ebook] Available at: <https://web.stanford.edu/~jurafsky/slp3/A.pdf> [Accessed 6 January 2021].
Kapadia, S., 2019. Language Models: N-Gram. [online] Medium. Available at: <https://towardsdatascience.com/introduction-to-language-models-n-gram-e323081503d9> [Accessed 6 January 2021].
Pythontic.com. n.d. Plotting A Spectrogram Using Python And Matplotlib | Pythontic.Com. [online] Available at: <https://pythontic.com/visualization/signals/spectrogram> [Accessed 6 January 2021].
Saha, S., 2018. A Comprehensive Guide To Convolutional Neural Networks — The ELI5 Way. [online] Medium. Available at: <https://towardsdatascience.com/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way-3bd2b1164a53> [Accessed 6 January 2021].
Scheidl, H., 2018. An Intuitive Explanation Of Connectionist Temporal Classification. [online] Medium. Available at: <https://towardsdatascience.com/intuitively-understanding-connectionist-temporal-classification-3797e43a86c> [Accessed 6 January 2021].
Venkatachalam, M., 2019. Recurrent Neural Networks. [online] Medium. Available at: <https://towardsdatascience.com/recurrent-neural-networks-d4642c9bc7ce> [Accessed 6 January 2021].
